密码学提升-哈希算法原理及C实现
For begin
app为什么需要so里面的代码
1 | 执行效率 |
so中会接触到的:系统库函数、加密算法、jni调用、系统调用、自写算法
so层没有标准加密库调用,无法像Java里那样messageDigest这么明显的识别
Hex编码
Hex 编码的基本步骤
将数据转换为二进制
- 每个字符或字节数据用 8 位二进制表示(1 字节 = 8 位)。
- 例如,字符
'A'的 ASCII 值是65,二进制表示为01000001。
按 4 位分组
将 8 位二进制分成两个 4 位的部分(每个 4 位称为一个 nibble)。
例如,
1
01000001
分为:
- 高 4 位:
0100 - 低 4 位:
0001
- 高 4 位:
将每个 4 位二进制转换为十六进制
每 4 位可以表示一个十六进制字符(
0-9和A-F)。对于
1
0100
和
1
0001
0100→40001→1
组合结果
- 将两个十六进制字符拼接起来,形成该字节的十六进制表示。
- 例如,
01000001→41。
完整示例
假设我们要对字符串 "Hi" 进行 Hex 编码:
步骤 1:获取每个字符的 ASCII 值
'H'→ ASCII 值72→ 二进制01001000'i'→ ASCII 值105→ 二进制01101001
步骤 2:分组并转换为十六进制
'H'的二进制01001000:- 高 4 位:
0100→4 - 低 4 位:
1000→8 - Hex 表示:
48
- 高 4 位:
'i'的二进制01101001:- 高 4 位:
0110→6 - 低 4 位:
1001→9 - Hex 表示:
69
- 高 4 位:
步骤 3:组合结果
"Hi"的 Hex 编码结果是:4869
MD5算法
C实现的MD5算法的使用
MD5.h
1 | // |
main.cpp
1 | // |
算法原理
明文的预处理
首先看明文是怎么处理的,即MD5Update(&context, plainText, strlen(reinterpret_cast<const char *>(plainText)));做了什么
步骤1:对明文进行Hex编码
1 | xiaojianbang ==> 78 69 61 6f 6a 69 61 6e 62 61 6e 67 |
步骤2:填充
先把明文填充到448bit,先填充一个1,后面跟对应个数的0(比特位的0)
所以这里明文就会被处理成
1 | 78 69 61 6f 6a 69 61 6e 62 61 6e 67 80 ... |
80就是标志着明文的结束,因为80在二进制层面就是 1000 0000,80的后面一直到448bit的地方就是全0了
再填充64bit的附加消息,用这64bit表示消息长度,如果内容过长,64bit放不下,就取低64bit
注意消息长度要取小端序,比如消息长度是 00 00 00 00 00 00 00 60,转小端序就是 60 00 00 00 00 00 00 00
最终明文处理之后的结果
1 | 78 69 61 6f 6a 69 61 6e 62 61 6e 67 80 ... 60 00 00 00 00 00 00 00 |
PS:附加消息
在 MD5 算法中,附加消息的最后 64 位表示的是明文的长度,而不是经过 Hex 编码后的长度。具体来说,它表示的是原始明文的长度(以比特为单位)。
明文长度:指的是原始数据的长度,单位是比特(bit)。例如,字符串 "hello" 中有 5 个字符,每个字符占用 1 字节(8 比特),因此明文长度是:
1 | 5 字符×8 比特/字符=40 比特 |
Hex 编码长度:如果将 "hello" 转为 Hex 编码,会变成 "68656c6c6f",共 10 个字符(每个原始字节用 2 个十六进制字符表示)。
但 MD5 的长度字段只关心原始明文的长度,而不考虑编码后的形式。
如果明文是 “hello”,64 位字段的值是什么?明文 "hello" 的长度是 5 字节,等于 40 比特,64 位字段会存储这个长度(40 比特),并以小端序(little-endian)格式存储。
存储过程:
将 40 转换为 64 位二进制:
1 | 40 (十进制)=0000000000000000000000000000000000000000000000000000000000101000 (二进制) |
按小端序排列(低字节在前,高字节在后):
1 | 001010000000000000000000000000000000000000000000000000000000000000101000 00000000 00000000 00000000 00000000 00000000 00000000 000000000010100000000000000000000000000000000000000000000000000000000000 |
以字节表示:
1 | 0x28 0x00 0x00 0x00 0x00 0x00 0x00 0x00 |
MD5的分组长度是512bit,填充位数为1-512bit,如果明文长度刚好为448bit,需要填充512bit,也就是有个512bit的新分组(这个分组由 1 位的 1、447 位的 0 和 64 位的附加消息(表示明文长度) 组成),且附加消息对于每个分组都是一样的,因为代表了明文的长度而不是分组的长度
字节序是字节的顺序不是比特的顺序,单字节不存在字节序
步骤3:明文分块
把处理之后的明文分成16块M1-M16,也就是每块32bit
| 实际的值 | 内存中的小端字节序 | |
|---|---|---|
| M1 | 78 69 61 6f | 6f 61 69 78 |
| M2 | 6a 69 61 6e | 6e 61 69 6a |
| M3 | 62 61 6e 67 | 67 6e 61 62 |
| M4 | 80 00 00 00 | 00 00 00 80 |
| … | ||
| M15 | 60 00 00 00 | 00 00 00 60 |
| M16 | 0 | 0 |
步骤4:初始化常量
1 | typedef struct { |
state[0]到state[4]就是4个初始化常量,注意这里也是以小端序标识的,实际内存中的初始化常量是 01 23 45 67 …
MD5魔改最多的也是这里的初始化常量
步骤5:MD5Transform
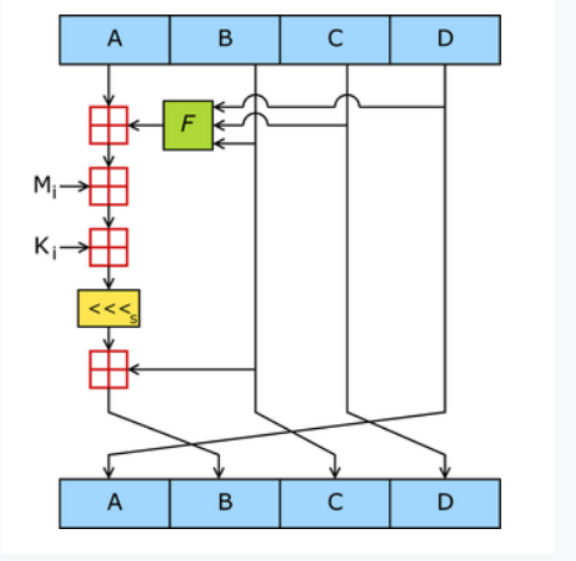
ABCB就是上面的四个初始化的常量,而且图上的转换是一轮,MD5有64轮
每轮都会让旧的ABCD生成新的ABCD,可以看到旧的B给了新的C、旧的C给了新的D、旧的D给了新的A,新的B是旧的A经过一番计算得来的,每轮只计算一个新的B,如果不考虑计算的话,可以简单理解为每轮都把最后的常量提到第一个
Mi就是上面分块的明文,ABCD、F、Ki都是标准MD5算法里规定好的,如果没魔改的话是不变的
1 | 图中的田代表相加 |
1 | typedef struct { |
1 | void MD5Update(MD5_CTX *context, unsigned char *input, unsigned int inputlen) { |
1 | // 大端序转小端序 |
还有一种字节序转换的方法
1 | char tmp[4] = {0x12,0x34,0x56,0x78}; |
SHA1算法
SHA1算法的初始化常量有5个,前4个与MD5一致,所以SHA1算法的结果有20字节,结果也是大端序
SHA1算法对于明文的处理与MD5相同,区别是最后的消息长度是大端序
SHA1的分组长度也是512bit,明文也要分段,类似Mi,区别是有80段,后64段是扩展出来的,遵循大端序
SHA1与SHA0的区别就是在扩展这64段的时候,增加了循环左移1位
SHA1的核心计算过程与MD5差不多,区别是K值只有4个,每个K值用20次,总共80轮
SHA1最后计算的结果也是大端序
demo
main.c
1 | // |
sha1.c
1 | /* |
sha1.h
1 | /* |
哈希算法的识别
MD5
初始化常量4个
K表 64个
输出长度16个字节,32个十六进制数,有时候输出16个十六进制数
SHA1
初始化常量5个,前四个和MD5完全相同
K表 4个,每20轮用同一个K作变换,总共80轮
输出长度20字节,40个十六进制数
SHA256
初始化常量8个
K表64个
输出长度32个字节,64个十六进制数
SHA512
初始化常量8个,IDA反编译时有时候显示为16个(字节数解析的问题,8个是8个16字节,解析成16个是被当成8字节每个去解析了)
K表80个
输出长度64字节,128个十六进制数
分组1024bit一组
HmacMD5算法
MAC算法
mac算法其实就是两次加盐,两次hash的一种hash算法
符号含义
1 | m 明文 |
HMAC算法公式
$$
MHAC(K,M) = H((K’⨁opad) || H((K’⨁ipad)||m))
$$
MAC算法也有可能是三次hash,多出来的这一次是针对密钥的,也就是K’和K的关系
如果K比block size大,那么K要进行hash运算得到K’,否则不用
HMACMD5算法步骤
步骤1:密钥扩展
密钥a12345678转Hex编码
1 | 61 31 32 33 34 35 36 37 38 |
然后填充0,让密钥长度达到算法的分组长度,MD5的话就是512bit
1 | 61 31 32 33 34 35 36 37 38 00 ... 00 00 |
如果密钥太长,就先进行MD5,再填充0,也就是16字节MD5值+一堆0
步骤2:扩展后的密钥与0x36异或
注意0x36也需要扩展到512bit,也就是一堆0x36,cyberchef里会自动扩展,但是代码里需要写
1 | 57 07 04 05 02 03 00 01 0e 36 36 .. 36 36 |
步骤3:异或后的数据与明文(message)级联
对应的是上面公式里的 (K'⨁ipad)||m)
1 | 57 07 04 05 02 03 00 01 0e 36 36 .. 36 36 61 31 32 33 34 35 36 37 38 |
步骤4:级联后的数据进行hash算法
对应上述的H((K'⨁ipad)||m))
步骤5:扩展之后的密钥与0x5c异或
对应上述的 (K'⨁opad) ,也就是opad之后的数据
步骤6:opad之后的数据与H((K’⨁ipad)||m))之后的数据进行级联
步骤7:步骤6的结果进行hash
得到最终结果
demo
1 | key |
代码实现
hmac_md5.h
1 |
|
hmac_md5.c
1 |
|
main.c
1 |
|
算法识别
大部分是hash算法,除了0x36和0x5c这个特征,十进制就是54和92
MD5、魔改的MD5、HmacMD5最后的结果都是16字节