AST基础
介绍
AST(AbstractSyntaxTree,抽象语法树)是一种树状结构,用于表示代码的语法结构.它是源代码在编译或解释执行之前的中间表示,能够捕获代码的语法规则和层级关系.
在AST中,代码的每个语法元素(如变量、函数、运算符等)都会被解析成一个节点,节点之间的层次结构表现出代码的嵌套关系.
demo
1 | let obj = { |
解析成语法树如下https://astexplorer.net/
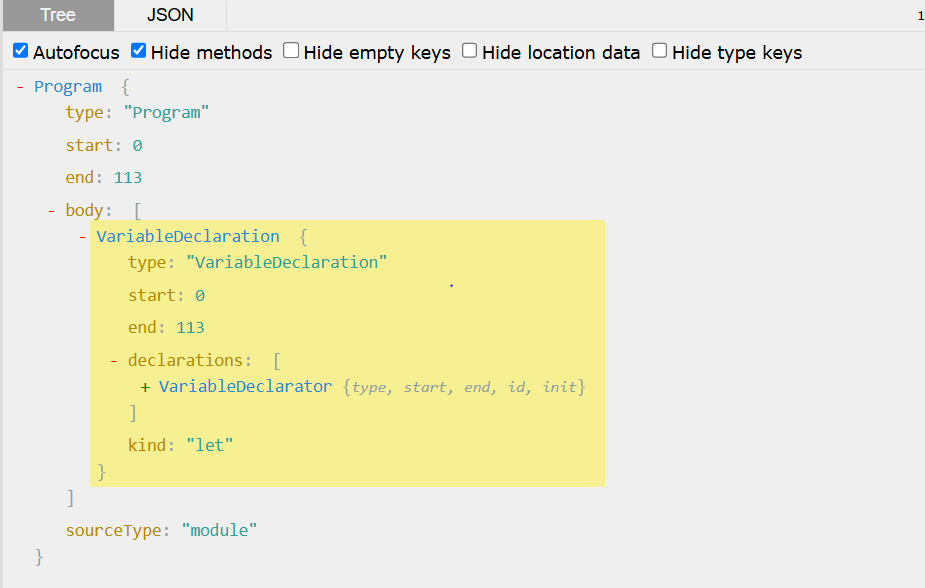
可以换成json来看
1 | { |
program属性的body属性是一个数组,该数组存放js代码的代码行
VariableDeclaration是变量声明,意思是这段js代码是变量声明语句,kind意思是变量声明使用的关键字,这里是let
这里的declarations是个数组,数组元素的个数和声明变量的个数一致
关注declarations下的id和init,id里面的name属性是变量名,init内是变量初始化的值,init的properties是键值对,是属性名和属性值
关注a+b+1000在AST中怎么表示的,按右边的+分隔,分成a+b和1000,再把a+b按+分隔,分成a和b
babel库可以对AST语法进行解析,后面都是用babel库进行操作的
代码的基本结构
demo
把原始代码保存成一个文件,名为demo.js,注意保存成utf-8编码的,另外新建一个文件,用来解析demo.js
这里的demo.js就是
1 | let obj = { |
安装babel库
1 | npm install @babel/core |
AST.js
1 | const fs = require('fs'); |
总的来说逻辑如下
1 | (1)fs用来读写本地文件,require之后赋值给了fs. |
parser和generator
这两个组件的作用刚好是相反的.parser组件用来将JS代码转换成AST,generator用来将AST转换成JS代码.
使用letast=parser.parse(jscode);即可完成JS代码转换到AST的过程,这时候把ast输出来,就是跟网页中解析出来的一样的结构,输出前通常先使用JSON.stringify把对象转json数据,例如,console.log(JSON.stringify(ast,null,2)).另外,parser的parse方法,其实是有第二个参数的
1 | letast=parser.parse(jscode,{ |
sourceType默认是script,但是当解析的JS代码中,含有import、export等关键字的时候,需指定sourceType为module.不然会报错
letcode=generator(ast).code;,这里的generator其实也有其他参数
1 | //retainLines表示是否使用与源代码相同的行号,默认true |
traverse与visitor
demo
先看demo,需要把下面代码中的a变量改成x变量
1 | let obj = { |
把上面的代码拿到ast网站上解析一下,需要知道a变量在ast中长什么样,在ast语法树中,a变量是使用Identifier节点表示的
1 | "params": [ |
traverse用来遍历语法树中所有的节点的,节点可以理解为数组中的成员,visitor则定义了遇到什么节点该做什么修改
1 | letvisitor={}; |
traverse的第一个参数是ast语法树,visitor是一个自定义的对象,该对象可以自己定义一些方法,方法名和节点名一样,比如要处理的是Identifer节点,那么方法名就是Identifer,属性是一个函数,函数的参数是path对象,什么是path对象后面会说,通过path对象可以对节点进行修改
当然上面的代码是不严谨的,因为不可能只根据变量名去改,作用域怎么办?
两者的作用
traverse组件用来遍历AST,简单地说就是把AST上的各个节点都走一遍,但是单纯的把节点都走一遍是没有意义的,所以taverse需要配合visitor使用.visitor是一个对象,里面可以定义一些方法,用来过滤节点.概念是抽象的,接下来用个实际案例试一下traverse和visitor的效果:
1 | letvisitor={}; |
先是声明对象,对象的名字可以随意,然后给对象增加了一个名为FunctionExprcssion的方法,这个名字是需要遍历的节点类型,注意大小写.
traverse会遍历所有的节点,当节点类型为FunctionExpression时,调用visitor中相应的方法,如果想要处理其他节点类型例如Identifier.可以在visitor中继续定义方法,以Identifer命名即可.
visitor中的方法接收一个参数,traverse在遍历的时候,会把当前节点的Path对象传给它,传过来的是Path对象而非节点(node)
最后把visitor作为第二个参数传到traverse里面,传给traverse的第一个参数是整个ast.这段代码的意思是,从头开始遍历ast中的所有节点,过滤出FunctionExpression节点,执行相应的方法,在原始代码中有两个FunctionExpression节点,因此会输出两次John.
visitor的三种定义方式
visitor的定义方式还有三种
1 | constvisitor1={ |
在visitor3中,存在一个重要的enter,在遍历节点过程中,实际上有两次机会来访问一个节点,即进入节点时(enter)与退出节点时(exit),比如这样定义
1 | let visitor = {}; |
以原始代码中的add函数为例,节点的遍历过程可描述如下:
1 | 进入FunctionExpression |
可以看出来是深度优先的搜索,正确的选择节点处理时机,有助于提高代码效率,可以看出traverse是一个深度优先的遍历过程,因此,如果存在父子节点,那么enter的处理时机是先处理父节点,再处理子节点,与此相反,exit的处理时机是先处理子节点,再处理父节点,traverse 默认就是在 enter时候处理,如果要在exit时候处理,必须在visitor中写明.
还可以把同一个函数用在多个节点上
1 | const visitor = { |
退出和进入的时候对同一个节点可以执行多个函数
1 | function test1(path) { |
现在还有一个问题,如果要修改变量的名有重名怎么办?我想修改指定作用域内的变量名,比如我只想修改函数内部的a变量
1 | let a=1000; |
指定一下遍历的是FunctionExpression节点内的子节点,并且是Identifier子节点
1 | let visitor = {}; |
现在来解释一下上面的语法
1 | (1)为什么enter里又定义了myVisitor? |
path.traverse还有第二个参数,是参数列表,比如现在想把代码里函数的第一个参数都修改为x,怎么办?
1 | let visitor = {}; |
现在对上面的代码进行解释
1 | (1)为什么不能直接用 path.node.params[0].name,而要提前存入 paramName 并通过 path.traverse(myVisitor, { paramName }) 传递 |
types组件
types判断节点类型
该组件主要用来判断节点类型,生成新的节点等,判断节点类型很简单,例如t.isldentifier(path.node),它等价于 path.node.type=="Identifier",还可以在判断类型的同时附加条件,演示案例如下
1 | const t = require("@babel/types"); |
types生成新节点
直接上代码,很好理解,也就是对着AST语法树的节点看需要添加什么节点,节点的属性是什么,子节点是什么
1 | let var_a = types.identifier('a'); |
valueToNode方法也可以生成各种字面量,和上面的代码功能一样,但是不能生成FunctionExpression节点
1 | console.log(types.valueToNode([1, "2", false, null, undefined, /\w\s/g, {x: '1000', y: 2000}])); |
path对象
先看这段代码
1 | let obj = { |
直接输出path
1 | const fs = require('fs'); |
结果可以看到path的属性是NodePath,NodePath下有node属性,从而得知node其实是path的一个属性
parentPath是当前节点的父节点的path对象
container,当container的值是一个数组的时候,代表当前节点是存在兄弟节点的
scope代表作用域
访问子节点属性
path对象提供了一系列api,可以方便的操作节点,还是以上面的demo为例,尝试访问BinaryExpression的子节点,就有两种方法
1 | traverse(ast, { |
语法转代码
1 | console.log(generator(path.node).code); |
替换节点属性
比如要替换代码中的a和b为x和y
1 | traverse(ast, { |
替换节点,比如要把上面的函数return改为返回字符串
1 | traverse(ast, { |
替换代码、删除和插入节点
替换return语句为其他语句,使用replaceWithSourceString方法
1 | traverse(ast, { |
父级path
前面输出的Path对象,可以看到有 parentPath和parent 两个属性。其中parentPath 类型为NodePah ,所以它是父级 Path。parent类型为 Node,所以它是父节点,因而只要获取到父级Path,就可以调用Path对象的各种方法去操作父节点了,父级Path 的获取可以使用 path.parentPath.
常用方法
path.findParent,向上遍历语法树,直到满足相应的条件返回
1 | traverse(ast, { |
Path 对象的 findParent 接收一个回调函数,在向上遍历每一个父级 Path 时,会调用该回调函数,并传入对应的父级Path 对象作为参数。当该回调函数返回真值时,则将对应的父级 Path 返回。上述代码会遍历 ReturnStatement,然后向上找父级 Path,当找到 Path 对象类型为 ObjectExpression的情况时,就返回该Path 对象.
path.getFunctionParent,向上查找与当前节点最接近的父函数 path.getFunctionParent 返回的也是 Path 对象
path.getStatementParent,向上遍历语法树,直到找到语句父节点,Statement语句包含很多,例如,声明语句、return语句、if语句、switch语句、while语句等等,返回的也是Path对象,该方法从当前节点开始找起,如果想要找到return 语句的父语句,就需要从parentPath中去调用,代码如下:
1 | console.log(path.parentPath.getStatementParent()); |
同级path
container
在介绍同级path之前,先介绍一下container
对于这段代码
1 | let obj = { |
运行
1 | traverse(ast, { |
这段解析的代码作用就是在 AST 遍历过程中,每当遇到 ReturnStatement 节点时,打印当前节点的 path
对于这一段函数代码
1 | add:function(a,b){ |
其container如下
1 | container: [ |
可以得出:
1 | container是一个数组,它存放了一组Node节点(AST 节点)。 |
几个问题
1 | (1)key是什么? |
所以container存储的是当前节点的同级节点
当然container不一定都是数组,也有不是数组的情况,对于这种情况,可以理解为当前节点没有兄弟节点
同级节点有关方法
1 | traverse(ast, { |
1 | path.inList 判断是否有同级节点 |
在container中插入节点,unshiftContainer是在容器头部插入节点,pushContainer是在容器后面插入节点
1 | traverse(ast, { |
scope对象
介绍
scope 提供了一些属性和方法,可以方便的查找标识符的作用域,获取标识符的所有引用,修改标识符的所有引用,以及知道标识符是否参数,标识符是否为常量,如果不是常量也可以知道在哪里修改了它,以下面的代码为例:
1 | const a = 1000; |
ast.js
1 | // 获取e变量的作用域范围,打印出作用域内的代码 |
几个问题
1 | (1)什么是绑定 |
referencePaths与constantViolations
在 Babel 的 AST 处理过程中,referencePaths 和 constantViolations 是 Binding 对象的属性,主要用于追踪变量的引用情况和是否被修改。它们是在 Babel 的作用域分析(Scope Analysis)阶段被定义的。
referencePaths,存储当前绑定(binding)的所有引用位置。定义在 Binding 对象中,包含所有引用了该变量的 Identifier 节点(但不包括声明)和不会包含对该变量的赋值位置(赋值的位置属于 constantViolations)
比如
1 | function test() { |
x 的 binding 可能类似于
1 | { |
referencePaths 包含 console.log(x) 和 return x + 5 的 Identifier 节点,但不包括 let x = 10;,因为 let 语句是变量的定义,不是引用。
constantViolations,存储所有可能修改变量值的位置。定义同样在 Binding 对象中,包含变量的重新赋值位置(如 x = 20;)、通过 ++, --, += 等操作修改变量的地方、如果是 const 声明,理论上 constantViolations 应该为空
比如
1 | function test() { |
x 的 binding 可能类似于
1 | { |
什么时候使用 referencePaths 和 constantViolations?
1 | 如果你想找到变量在代码中的所有引用(如 console.log(x)),用referencePaths。 |
查看绑定的referencePaths?
1 | traverse(ast, { |
输出大概长这样
1 | [ |
先说明几个问题
1 | (1)为什么输出有两个Node? |
constantViolations也同理了,所以可以根据标识符的binding去修改代码
1 | traverse(ast, { |
遍历作用域
前面说过,使用path.scope.block可以获取作用域,但是针对函数的话,需要path.scope.parent.block获取作用域,而binding.scope可以直接获取,不需要考虑是变量还是函数
1 | traverse(ast, { |
标识符重命名
scope.generateUidIdentifier可以返回不容易重名的变量名
1 | traverse(ast, { |