所有例子针对的代码如下
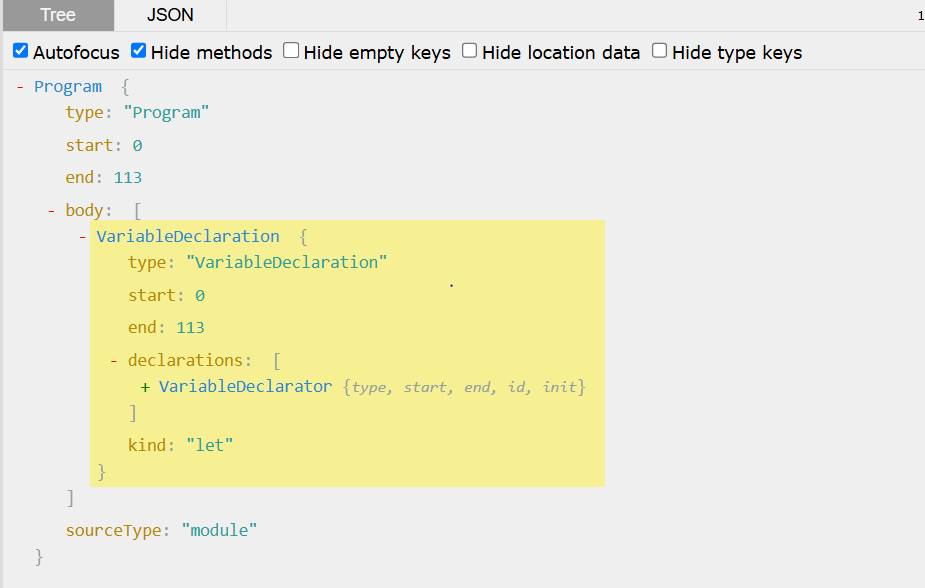
1 2 3 4 5 6 7 8 9 Date .prototype format = function (formatStr ) { var str = formatStr; var Week = ['日' , '一' , '二' , '三' , '四' , '五' , '六' ]; str = str.replace (/yyyy|YYYY/ , this .getFullYear ()); str = str.replace (/MM/ , (this .getMonth () + 1 ) > 9 ? (this .getMonth () + 1 ).toString () : '0' + (this .getMonth () + 1 )); str = str.replace (/dd|DD/ , this .getDate () > 9 ? this .getDate ().toString () : '0' + this .getDate ()); return str; } console .log ( new Date ().format ('yyyy-MM-dd' ) );
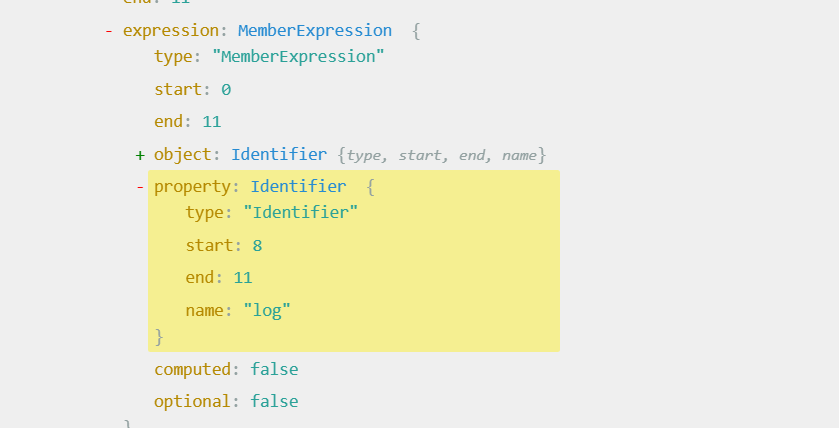
改变对象属性访问方式 对象的属性访问方式有两种,即console.log和console["log"],在js混淆中,通常会使用类似后者的方式去访问对象的属性
先看一下这两种方式在AST中的区别,第一个是.log的,第二个是[“log”]的
重点关注这里的computed是true还是false,也就是说只要能把代码AST语法树的computed从false改为true,就可以把源代码中的.方式调用改为[]方式调用
代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 const fs = require ('fs' );const parser = require ("@babel/parser" );const traverse = require ("@babel/traverse" ).default ;const types = require ("@babel/types" );const generator = require ("@babel/generator" ).default ;const jscode = fs.readFileSync ("./demo.js" , { encoding : "utf-8" }); let ast = parser.parse (jscode);traverse (ast, { MemberExpression (path) { if (types.isIdentifier (path.node .property )) { let name = path.node .property .name ; path.node .property = types.stringLiteral (name); } path.node .computed = true ; }, }) let code = generator (ast).code ;fs.writeFile ('./demoNew.js' , code, (err )=> {});
JS标准内置对象的处理 在经过改变访问方式后的代码中,可以看到有两个Date,这是JS中的标准内置对象,也可以理解为系统函数,系统函数的使用必须按照规则来,内置对象一般都是window下的属性,因此可以转化为 window["Date"]这种形式来访问,这样的Date是一个字符串,可以进行加密。另外,还有一些系统自带的全局所数,它们也是window下的方法,可以一并处理。
JS发展到现在,标准内置对象已经极其庞杂,这里只演示其中的一部分,JS中的常见的全局函数有 eval、parselnt、encodeURIComponent
JS中常见的标准内置对象有 Object、Function、Boolean、Number、Math、Date、String、RegExp、Array等
这些全局所数和内置对象都是window对象下的,在AST中都是标识符,因此处理代码的过程可以是遍历Identifier节点,把符合要求的节点替换成object属性为 window 的MemberExpression,也就是需要生成MemberExpression
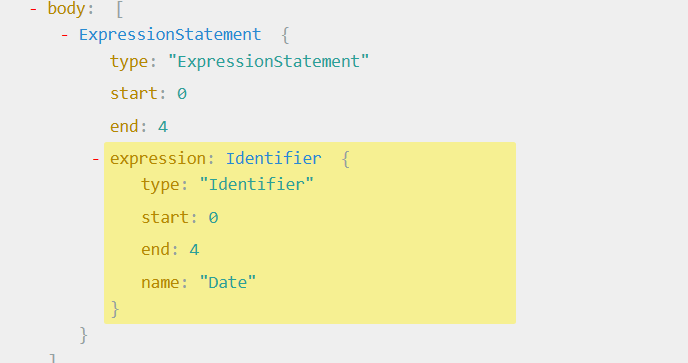
比如对于Date节点来讲,如果不加window的话,长这样
改成window["Date"]的话,是这样
也就是说,找到Date的Identifier节点,然后替换成MemberExpression
代码如下
1 2 3 4 5 6 7 8 traverse (ast, { Identifier (path){ let name = path.node .name ; if ('eval|parseInt|encodeURIComponent|Object|Function|Boolean|Number|Math|Date|String|RegExp|Array' .indexOf ('|' + name + '|' ) != -1 ){ path.replaceWith (types.memberExpression (types.identifier ('window' ), types.stringLiteral (name), true )); } }, })
数值常量加密 代码中的数值常量可以通过遍历NumericLiteral节点,获取其中的value属性得到,然后随机生成一个数值记为key,接着把value与key进行异或,得到加密后的数值记为cipherNum,即cipherNum=value^key,此时value=cipherNum^key,因此可以生成一个BinaryExpression节点来等价的替换 NumericLiteral 节点,BinaryExpression的operator 为 ^,left为cipherNum,right为key,具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 traverse (ast,{ NumericLiteral (path){ let value = path.node .value ; let key = parseInt (Math .random () * (999999 - 100000 ) + 100000 , 10 ); let cipherNum = value ^ key; console .log (generator (types.binaryExpression ('^' , types.numericLiteral (cipherNum), types.numericLiteral (key))).code ); path.replaceWith (types.binaryExpression ('^' , types.numericLiteral (cipherNum), types.numericLiteral (key))); path.skip (); } })
字符串常量加密 原始代码经过前面的处理,许多标识符都变成了字符串,但是这些字符串依然是明文。
现在就要对这些字符串进行加密,加密的思路较为简单,例如代码中明文是"prototype",加密后的值为"cHJvdG90eXB",解密函数名为atob。只要生成一下atob("cHJvdG90cXBI"),然后用它替换原先的"prototype"即可,当然解密函数也需要一起放入原始代码中。
在这里就用 Base64 编码一下字符串,然后使用浏览器自带的 atob 来解密,在 AST 中操作的话,要先遍历所有的 StringLiteral,取出其中的 value 属性进行加密,然后把 StringLiteral 节点替换为 CallExpression(调用表达式)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 const fs = require ('fs' );const parser = require ("@babel/parser" );const traverse = require ("@babel/traverse" ).default ;const types = require ("@babel/types" );const generator = require ("@babel/generator" ).default ;const jscode = fs.readFileSync ("./demo.js" , { encoding : "utf-8" }); let ast = parser.parse (jscode);function base64_encode (str ) { var c1, c2, c3; var base64EncodeChars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=" ; var i = 0 , len = str.length , strin = '' ; while (i < len) { c1 = str.charCodeAt (i++) & 0xff ; if (i == len) { strin += base64EncodeChars.charAt (c1 >> 2 ); strin += base64EncodeChars.charAt ((c1 & 0x3 ) << 4 ); strin += "==" ; break ; } c2 = str.charCodeAt (i++); if (i == len) { strin += base64EncodeChars.charAt (c1 >> 2 ); strin += base64EncodeChars.charAt (((c1 & 0x3 ) << 4 ) | ((c2 & 0xF0 ) >> 4 )); strin += base64EncodeChars.charAt ((c2 & 0xF ) << 2 ); strin += "=" ; break ; } c3 = str.charCodeAt (i++); strin += base64EncodeChars.charAt (c1 >> 2 ); strin += base64EncodeChars.charAt (((c1 & 0x3 ) << 4 ) | ((c2 & 0xF0 ) >> 4 )); strin += base64EncodeChars.charAt (((c2 & 0xF ) << 2 ) | ((c3 & 0xC0 ) >> 6 )); strin += base64EncodeChars.charAt (c3 & 0x3F ) } return strin } function test (ast ){ traverse (ast, { MemberExpression (path) { if (types.isIdentifier (path.node .property )) { let name = path.node .property .name ; path.node .property = types.stringLiteral (name); } path.node .computed = true ; }, }) traverse (ast, { Identifier (path){ let name = path.node .name ; if ('eval|parseInt|encodeURIComponent|Object|Function|Boolean|Number|Math|Date|String|RegExp|Array' .indexOf ('|' + name + '|' ) != -1 ){ path.replaceWith (types.memberExpression (types.identifier ('window' ), types.stringLiteral (name), true )); } }, }) traverse (ast,{ NumericLiteral (path){ let value = path.node .value ; let key = parseInt (Math .random () * (999999 - 100000 ) + 100000 , 10 ); let cipherNum = value ^ key; console .log (generator (types.binaryExpression ('^' , types.numericLiteral (cipherNum), types.numericLiteral (key))).code ); path.replaceWith (types.binaryExpression ('^' , types.numericLiteral (cipherNum), types.numericLiteral (key))); path.skip (); } }) traverse (ast, { StringLiteral (path){ let cipherText = base64_encode (path.node .value ); let encStr = types.callExpression (types.identifier ('base64_decode' ), [types.StringLiteral (cipherText)]); path.replaceWith (encStr); path.skip (); } }) } test (ast)let code = generator (ast).code ;fs.writeFile ('./demoNew.js' , code, (err )=> {});
数组混淆 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 let window = global ;function base64_decode (input ) { var base64EncodeChars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=" ; var output = "" ; var chr1, chr2, chr3; var enc1, enc2, enc3, enc4; var i = 0 ; input = input.replace (/[^A-Za-z0-9\+\/\=]/g , "" ); while (i < input.length ) { enc1 = base64EncodeChars.indexOf (input.charAt (i++)); enc2 = base64EncodeChars.indexOf (input.charAt (i++)); enc3 = base64EncodeChars.indexOf (input.charAt (i++)); enc4 = base64EncodeChars.indexOf (input.charAt (i++)); chr1 = (enc1 << 2 ) | (enc2 >> 4 ); chr2 = ((enc2 & 15 ) << 4 ) | (enc3 >> 2 ); chr3 = ((enc3 & 3 ) << 6 ) | enc4; output = output + String .fromCharCode (chr1); if (enc3 != 64 ) { output = output + String .fromCharCode (chr2); } if (enc4 != 64 ) { output = output + String .fromCharCode (chr3); } } return utf8_decode (output); } function utf8_decode (utftext ) { var string = '' ; let i = 0 ; let c = 0 ; let c1 = 0 ; let c2 = 0 ; while (i < utftext.length ) { c = utftext.charCodeAt (i); if (c < 128 ) { string += String .fromCharCode (c); i++; } else if ((c > 191 ) && (c < 224 )) { c1 = utftext.charCodeAt (i + 1 ); string += String .fromCharCode (((c & 31 ) << 6 ) | (c1 & 63 )); i += 2 ; } else { c1 = utftext.charCodeAt (i + 1 ); c2 = utftext.charCodeAt (i + 2 ); string += String .fromCharCode (((c & 15 ) << 12 ) | ((c1 & 63 ) << 6 ) | (c2 & 63 )); i += 3 ; } } return string; } window [base64_decode ("RGF0ZQ==" )][base64_decode ("cHJvdG90eXBl" )][base64_decode ("Zm9ybWF0" )] = function (formatStr ) { var str = formatStr; var Week = [base64_decode ("5Q==" ), base64_decode ("AA==" ), base64_decode ("jA==" ), base64_decode ("CQ==" ), base64_decode ("2w==" ), base64_decode ("lA==" ), base64_decode ("bQ==" )]; str = str[base64_decode ("cmVwbGFjZQ==" )](/yyyy|YYYY/ , this [base64_decode ("Z2V0RnVsbFllYXI=" )]()); str = str[base64_decode ("cmVwbGFjZQ==" )](/MM/ , this [base64_decode ("Z2V0TW9udGg=" )]() + (197833 ^ 197832 ) > (887483 ^ 887474 ) ? (this [base64_decode ("Z2V0TW9udGg=" )]() + (202459 ^ 202458 ))[base64_decode ("dG9TdHJpbmc=" )]() : base64_decode ("MA==" ) + (this [base64_decode ("Z2V0TW9udGg=" )]() + (638772 ^ 638773 ))); str = str[base64_decode ("cmVwbGFjZQ==" )](/dd|DD/ , this [base64_decode ("Z2V0RGF0ZQ==" )]() > (768075 ^ 768066 ) ? this [base64_decode ("Z2V0RGF0ZQ==" )]()[base64_decode ("dG9TdHJpbmc=" )]() : base64_decode ("MA==" ) + this [base64_decode ("Z2V0RGF0ZQ==" )]()); return str; }; console [base64_decode ("bG9n" )](new window [base64_decode ("RGF0ZQ==" )]()[base64_decode ("Zm9ybWF0" )](base64_decode ("eXl5eS1NTS1kZA==" )));
来观察一下经过字符串加密以后的代码,可以看到字符串虽然加密了,但是依然在原先的位置。
数组混淆要做的事情,就是把这些字符串都提取到数组中,原先字符串的地方改为以数组下标的方式去访问数组成员,其实还可以提取到多个数组中,不同的数组处于不同的作用域中,在这里就只实现一下提取到一个数组的情况。
举个例子,如 Date[atob("cHJvdG90eXB")],把"cHJvdG90eXB"变成数组 arr 的下标为0的成员后,原先字符中的位置就变为 Date[atob(arr[0])],当然还需要额外生成一个数组,放入到被混淆的代码中
AST 的处理首先是遍历 StringLiteral节点,既然这个也是遍历 StringLiteral 节点,那么就可以和学符串加密一起处理了
arr[0]这种表达式是MemberExpression
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 let bigArr = [];traverse (ast, { StringLiteral (path){ let cipherText = base64_encode (path.node .value ); let index = bigArr.indexOf (cipherText); if (index == -1 ) { index = bigArr.push (cipherText) - 1 ; } let tmpMember = types.memberExpression (types.identifier ('arr' ), types.numericLiteral (index), true ); let encStr = types.callExpression (types.identifier ('base64_decode' ), [tmpMember]); path.replaceWith (encStr); path.skip (); } });
数组乱序 经过数组混淆以后的代码,引用处的数组索引与原先字符中还是一一对应的,现在就要打乱这个数组的顺序,代码较为简单,传一个数组进去,并且指定循环次数,每次循环都把数组后面的成员放前面
1 2 3 4 5 6 7 8 (function (myArr, num ){ var xiaojianbang = function (nums ){ while (--nums){ myArr.unshift (myArr.pop ()); } }; xiaojianbang (++num); }(bigArr, 0x10 ));
既然数组的顺序和原先不一样了,那么被混淆的代码在执行之前是需要还原的,因此还需要一段还原数组顺序的代码。这里的代码逆向编写即可,循环同样的次数,把数组前面的成员放后面
1 2 3 4 5 6 7 8 (function (myArr, num ) { var xiaojianbang = function (nums ) { while (--nums) { myArr.push (myArr.shift ()); } }; xiaojianbang (++num); })(arr, 0x10 );
十六进制文本 实现数组顺序还原的代码是没有经过混淆的,代码中标识符的混淆,可以在最后一起处理,其中像 push、shift 这些方法可以转为字符串,由于这些代码处于还原数组顺序的代码中,因此没法把它们提取到大数组中,在这里就简单地把它们编码成十六进制字符串,也就是说myarr["\x70\x75\x73\x68"],是会被解析成myarr["push"]的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 function encode16 (ast ){ function hexEnc (code ) { for (var hexStr = [], i = 0 , s; i < code.length ; i++) { s = code.charCodeAt (i).toString (16 ); hexStr += "\\x" + s; } return hexStr } traverse (ast, { MemberExpression (path){ if (types.isStringLiteral (path.node .property )){ let value = path.node .property .value ; path.node .property = types.stringLiteral (hexEnc (value)); } path.node .computed = true ; } }); } encode16 (ast);
标识符混淆 一般情况下,标识符都是有语义的,根据标识符名可以大致推测出代码意图,因此标识符混淆很有必要,实际开发中,可以让各个函数之问的局部标识符名相同,函数内的局部标识符名还可以与没有引用到的全局标识符名相同,这样做更具迷惑性。
这里的demo主要是实现这种方案,需要用到一个方法 scope.getOwnBinding,该方法可以用来获取属于当前节点的自己的绑定,例如,在Program节点下,使用 getOwnBinding 就可以获取到全局标识符名,而函数内局部标识符名不会被获取到。那么要获取到局部标识符名,可以遍历函数节点,在FunctionExpression与FunctionDeclaration节点下,使用 getOwnBinding 会获取到函数自身定义的局部标识符名,而不会获取到全局标识符名,遍历三种节点,执行同一个重命名方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 function generatorIdentifier (decNum ){ let flag = ['O' , 'o' , '0' ]; let retval = []; while (decNum > 0 ){ retval.push (decNum % 3 ); decNum = parseInt (decNum / 3 ); } let Identifier = retval.reverse ().map (function (v ){ return flag[v] }).join ('' ); Identifier .length < 6 ? (Identifier =('OOOOOO' + Identifier ).substr (-6 )): Identifier [0 ] == '0' && (Identifier = 'O' + Identifier ); return Identifier ; } function renameOwnBinding (path ) { let OwnBindingObj = {}, globalBindingObj = {}, i = 0 ; path.traverse ({ Identifier (p) { let name = p.node .name ; let binding = p.scope .getOwnBinding (name); binding && generator (binding.scope .block ).code == path + '' ? (OwnBindingObj [name] = binding) : (globalBindingObj[name] = 1 ); } }); for (let oldName in OwnBindingObj ) { do { var newName = generatorIdentifier (i++); } while (globalBindingObj[newName]); OwnBindingObj [oldName].scope .rename (oldName, newName); } } traverse (newAst, { 'Program|FunctionExpression|FunctionDeclaration' (path) { renameOwnBinding (path); } }); code = generator (newAst).code ;
这段代码是获取全局绑定
1 2 3 4 5 6 7 8 path.traverse ({ Identifier (p) { let name = p.node .name ; let binding = p.scope .getOwnBinding (name); binding && generator (binding.scope .block ).code == path + '' ? (OwnBindingObj [name] = binding) : (globalBindingObj[name] = 1 ); } });
上述代码先遍历当前节点中所有的Identifer,得到 Identifier 的 name 属性,通过getOwnBinding判断是否为当前节点自己的绑定。
如果binding为undefined,则表示是其父级函数的标识符或者全局的标识符,就将该标识符名作为属性名,放入到globalBindingObj对象中,如果binding存在,则表示是当前节点自己的绑定,就将该标识符作为属性名、binding作为属性值,放入到OwnBindingObj对象中。
这里有几点需要注意一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1)globalBindingObj中存放的不是所有的全局标识符,而是当前节点引用到的全局标识符。因为重命名标识符的时候,不能与引用到的全局标识符重名,需要进行判断。至于没有引用到的全局标识符名,就是要重名才更具迷惑性,反正最后使用的还是当前节点定义的局部标识符。 例如: let xxxxx = 100; function test(){ xxxxx = 200; let aaa = 100; } 这里获取不到xxxxx的绑定,因为是全局变量,但是还是要存储,因为重命名aaa的时候不能与xxxxx重名 2)OwnBindingObj中存储对应标识符的binding,因为重命名标识符的时候,需要使用binding.scope.rename方法。 3)把标识符名作为对象的属性名。因为一个Identifier有多处引用就会遍历到多个,但实际上只需要调用一次scope.rename即可完成所有引用处的重命名,而对象属性名具有唯一性,就可以只保留最后一个同名标识符。 例如: function test(){ let x = 100; x = x +100; } x会被遍历到多次,但是只存储最后一次,实际上不影响
接下去要遍历OwnBindingObj对象中的属性,来进行重命名,代码如下:
1 2 3 4 5 6 for (let oldName in OwnBindingObj ) { do { var newName = generatorIdentifier (i++); } while (globalBindingObj[newName]); OwnBindingObj [oldName].scope .rename (oldName, newName); }
二项式转函数花指令 花指令用来尽可能地隐藏原代码的真实意图,并且有许多种实现方案。
这里要介绍的是把二项式转为函数,例如,要把c+d,转换为以下这种形式:
1 2 3 4 function xxx (a,b ){ return a+b; } xxx (c,d);
不止二项式,代码中的函数调用表达式,也可以转换为花指令,例如c(d),可以转换为
1 2 3 4 function xxx (a,b ){ return a (b); } xxx (c,d);
在这里只实现二项式的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 1)遍历BinaryExpression节点,取出operator、left、right 2)生成一个函数,函数名要与当前节点中的标识符不冲突,参数可以固定为a和b,返回语句中的运算符与operator一致 3)找到最近的BlockStatement节点,将生成的函数加入到body数组中的最前面,也就是把函数往父函数的函数体内放,这样才能调用 function test(){ function xxx(c,b){ return c+b; } xxx(c,b); } 4)把原先的BinaryExpression节点替换为CallExpression,callee就是函数名,arguments就是二项式的left和right
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 traverse (ast, { BinaryExpression (path){ let operator = path.node .operator ; let left = path.node .left ; let right = path.node .right ; let a = types.identifier ('a' ); let b = types.identifier ('b' ); let funcNameIdentifier = path.scope .generateUidIdentifier ('xxx' ); let func = types.functionDeclaration ( funcNameIdentifier, [a, b], types.blockStatement ([types.returnStatement (types.binaryExpression (operator, a, b))])); let BlockStatement = path.findParent (function (p ){return p.isBlockStatement ()}); if (BlockStatement ){ BlockStatement .node .body .unshift (func); path.replaceWith (types.callExpression (funcNameIdentifier, [left, right])); } },
现在就是函数形式的怎么加花指令
1 2 3 4 function xxx (a,b ){ return a (b); } xxx (c,d);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 CallExpression (path) { let callee = path.node .callee ; let args = path.node .arguments ; if (!types.isMemberExpression (callee)) { let newArgs = []; for (let i = 0 ; i < args.length + 1 ; i++) { newArgs.push (path.scope .generateUidIdentifier ('a' )); } let funcNameIdentifier = path.scope .generateUidIdentifier ('xxx' ); let func = types.functionDeclaration ( funcNameIdentifier, newArgs, types.blockStatement ([ types.returnStatement ( types.callExpression (newArgs[0 ], newArgs.slice (1 )))])); let BlockStatement = path.findParent (function (p ){return p.isBlockStatement ()}); if (BlockStatement ){ BlockStatement .node .body .unshift (func); args.unshift (callee); path.replaceWith (types.callExpression (funcNameIdentifier, args)); } path.skip (); }
代码的逐行加密 先把代码转字符串,再把字符串加密之后的密文丢到eval里执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 traverse (newAst, { 'FunctionExpression|FunctionDeclaration' (path){ let blockStatement = path.node .body ; let Statements = blockStatement.body .map (function (v ){ if (types.isReturnStatement (v)) return v; if (!(v.trailingComments && v.trailingComments [0 ].value == 'Base64Encrypt' )) return v; delete v.trailingComments ; let code = generator (v).code ; let cipherText = base64_encode (code); let decryptFunc = types.callExpression (types.identifier ('atob' ), [types.stringLiteral (cipherText)]); return types.expressionStatement (types.callExpression (types.identifier ('eval' ), [decryptFunc])); }); path.get ('body' ).replaceWith (types.blockStatement (Statements )); } });
但是不建议大规模应用这种方式,可能带来变量作用域的问题,有的时候需要把let改为var才能执行
流程平坦化 也就是把原来函数体内的代码放到数组里,然后用switch去执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 Date .prototype format = function (formatStr ) { let _array = "0|1|4|5|3|2" .split ("|" ), _index = 0 ; while (!![]) { switch (+_array[_index++]) { case 0 : var str = formatStr; continue ; case 1 : var Week = ['日' , '一' , '二' , '三' , '四' , '五' , '六' ]; continue ; case 2 : return str; continue ; case 3 : str = str.replace (/dd|DD/ , this .getDate () > 9 ? this .getDate ().toString () : '0' + this .getDate ()); continue ; case 4 : str = str.replace (/yyyy|YYYY/ , this .getFullYear ()); continue ; case 5 : str = str.replace (/MM/ , (this .getMonth () + 1 ) > 9 ? (this .getMonth () + 1 ).toString () : '0' + (this .getMonth () + 1 )); continue ; } break ; } }; console .log (new Date ().format ('yyyy-MM-dd' ));
因为采用的是一行语句对应一条case的方案,所以需要先获取到每一行语句,处理办法与之前介绍的代码逐行混淆一致,遍历FunctionExpression节点,获取path.node.body即BlockStatement,该节点的body属性是一个数组,通过map方法遍历数组,即可操作其中的每一行语句,代码如下:
1 2 3 4 5 6 traverse (newAst, { FunctionExpression (path){ let blockStatement = path.node .body ; let Statements = blockStatement.body .map (function (v, i ){ return {index : i, value : v}; });
在流程平坦化的混淆中,要打乱原先的语句顺序,但是在执行的时候又要按原先的顺序执行,因此在打乱语句顺序之前,先要对原先的语句顺序做一下映射,从上述代码中可以看出,采用的是{index:i,value:v}这种方式来做映射,index是语句在blockStatement.body中的索引,也就是原先的顺序,value就是语句本身,有了这一一对应的关系后,就可以方便地建立分发器,来控制代码在执行时跳转到正确的case语句块j的成员与索引为i的成员进行交换。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 traverse (newAst, { FunctionExpression (path) { let blockStatement = path.node .body ; let Statements = blockStatement.body .map (function (v, i ) { return {index : i, value : v}; }); let i = Statements .length ; while (i) { let j = Math .floor (Math .random () * i--); [Statements [j], Statements [i]] = [Statements [i], Statements [j]]; } let dispenserArr = []; let cases = []; Statements .map (function (v, i ) { dispenserArr[v.index ] = i; let switchCase = types.switchCase (types.numericLiteral (i), [v.value , types.continueStatement ()]); cases.push (switchCase); }); let dispenserStr = dispenserArr.join ('|' ); let array = path.scope .generateUidIdentifier ('array' ); let index = path.scope .generateUidIdentifier ('index' ); let callee = types.memberExpression (types.stringLiteral (dispenserStr), types.identifier ('split' )); let arrayInit = types.callExpression (callee, [types.stringLiteral ('|' )]); let varArray = types.variableDeclarator (array, arrayInit); let varIndex = types.variableDeclarator (index, types.numericLiteral (0 )); let dispenser = types.variableDeclaration ('let' , [varArray, varIndex]); let updExp = types.updateExpression ('++' , index); let memExp = types.memberExpression (array, updExp, true ); let discriminant = types.unaryExpression ("+" , memExp); let switchSta = types.switchStatement (discriminant, cases); let unaExp = types.unaryExpression ("!" , types.arrayExpression ()); unaExp = types.unaryExpression ("!" , unaExp); let whileSta = types.whileStatement (unaExp, types.blockStatement ([switchSta, types.breakStatement ()])); path.get ('body' ).replaceWith (types.blockStatement ([dispenser, whileSta])); } });
但是现在把代码中加上一个while循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Date .prototype format = function (formatStr ) { var str = formatStr; var Week = ['日' , '一' , '二' , '三' , '四' , '五' , '六' ]; str = str.replace (/yyyy|YYYY/ , this .getFullYear ()); str = str.replace (/MM/ , (this .getMonth () + 1 ) > 9 ? (this .getMonth () + 1 ).toString () : '0' + (this .getMonth () + 1 )); str = str.replace (/dd|DD/ , this .getDate () > 9 ? this .getDate ().toString () : '0' + this .getDate ()); var index = 10 ; while (--index){ var tmp = 10 ; var tmpStr = 'index + tmp = ' ; console .log (tmpStr + (index + tmp)); } return str; } console .log ( new Date ().format ('yyyy-MM-dd' ) );
如果是原来的代码,会把整个while代码块放到一个代码块中,但是现在有个需求,需要把while代码块中的内容也分成多个case语句块,行不行呢?怎么知道while代码中有多少行代码呢?按照原先的方案是无法知道的,也不知道while循环要循环多少次
针对这种while语句,这里有一个demo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 let _index = 'i' ;let index, tmpStr, tmp;while (!![]) { switch (_index) { case 'i' : index = 10 ; _index = 'c' ; continue ; case 'c' : --index ? _index = 'j' : _index = 'dd' ; continue ; case 'j' : tmp = 10 ; _index = 'k' ; continue ; case 'k' : tmpStr = 'index + tmp = ' ; _index = 'z' ; continue ; case 'z' : console .log (tmpStr + (index + tmp)); _index = 'c' ; continue ; case 'dd' : break ; } break ; } console .log ('xiaojianbang' );
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 traverse (ast, { FunctionExpression (path) { let blockStatement = path.node .body ; let _index = path.scope .generateUidIdentifier ('index' ); let varIndex = types.variableDeclarator (_index, types.numericLiteral (0 )); let initor = types.variableDeclaration ('let' , [varIndex]); let cases = [], lastIndex = blockStatement.body .length - 1 , index, contiOrBreak, switchCase; blockStatement.body .map (function (v, i ) { if (i != lastIndex) { contiOrBreak = types.continueStatement (); } else { contiOrBreak = types.breakStatement (); } index = types.assignmentExpression ('=' , _index, types.numericLiteral (i + 1 )); if (types.isWhileStatement (v)) { let test = v.test ; let bodyArr = v.body .body ; let whileLastIndex = bodyArr.length - 1 ; bodyArr.map (function (val, ind ) { let whileIndex; if (ind != whileLastIndex) { whileIndex = types.assignmentExpression ('=' , _index, types.numericLiteral (lastIndex + ind + 1 + 1 )); } else { whileIndex = types.assignmentExpression ('=' , _index, types.numericLiteral (i)); } whileIndex = types.expressionStatement (whileIndex); switchCase = types.switchCase (types.numericLiteral (lastIndex + ind + 1 ), [val, whileIndex, types.continueStatement ()]); cases.push (switchCase); }); let whileIndex = types.assignmentExpression ('=' , _index, types.numericLiteral (lastIndex + 0 + 1 )); let conditional = types.conditionalExpression (test, whileIndex, index); switchCase = types.switchCase (types.numericLiteral (i), [types.expressionStatement (conditional), contiOrBreak]); cases.push (switchCase); } else { switchCase = types.switchCase (types.numericLiteral (i), [v, types.expressionStatement (index), contiOrBreak]); cases.push (switchCase); } }); let i = cases.length ; while (i) { let j = Math .floor (Math .random () * i--); [cases[j], cases[i]] = [cases[i], cases[j]]; } let switchSta = types.switchStatement (_index, cases); let unaExp = types.unaryExpression ("!" , types.arrayExpression ()); unaExp = types.unaryExpression ("!" , unaExp); let whileSta = types.whileStatement (unaExp, types.blockStatement ([switchSta, types.breakStatement ()])); path.get ('body' ).replaceWith (types.blockStatement ([initor, whileSta])); } });
还可以把case块不用数字,用字符串,这样更具有迷惑性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 traverse (ast, { FunctionExpression (path) { let blockStatement = path.node .body ; let staCount = blockStatement.body .length ; blockStatement.body .map (function (v ) { if (types.isWhileStatement (v)) { staCount += v.body .body .length ; } ; }); let caseTestArr = []; while (caseTestArr.length != staCount * 2 ) { let n = Math .random ().toString (36 ).substr (2 , 10 ); if (caseTestArr.indexOf (n) == -1 ) { caseTestArr.push (n); } } console .log (staCount, caseTestArr); let _index = path.scope .generateUidIdentifier ('index' ); let varIndex = types.variableDeclarator (_index, types.stringLiteral (caseTestArr[0 ])); let initor = types.variableDeclaration ('let' , [varIndex]); let cases = [], lastIndex = blockStatement.body .length - 1 , index, contiOrBreak, switchCase; let ii = 0 ; blockStatement.body .map (function (v ) { if (ii != lastIndex) { contiOrBreak = types.continueStatement (); } else { contiOrBreak = types.breakStatement (); } index = types.assignmentExpression ('=' , _index, types.stringLiteral (caseTestArr[ii + 1 ])); if (types.isWhileStatement (v)) { let test = v.test ; let bodyArr = v.body .body ; let whileLastIndex = bodyArr.length - 1 ; bodyArr.map (function (val, ind ) { let whileIndex; if (ind != whileLastIndex) { whileIndex = types.assignmentExpression ('=' , _index, types.stringLiteral (caseTestArr[ii + ind + 1 + 1 ])); } else { whileIndex = types.assignmentExpression ('=' , _index, types.stringLiteral (caseTestArr[ii])); } whileIndex = types.expressionStatement (whileIndex); switchCase = types.switchCase (types.stringLiteral (caseTestArr[ii + ind + 1 ]), [val, whileIndex, types.continueStatement ()]); cases.push (switchCase); }); let whileIndex = types.assignmentExpression ('=' , _index, types.stringLiteral (caseTestArr[ii + 1 ])); index = types.assignmentExpression ('=' , _index, types.stringLiteral (caseTestArr[ii + bodyArr.length + 1 ])); let conditional = types.conditionalExpression (test, whileIndex, index); switchCase = types.switchCase (types.stringLiteral (caseTestArr[ii]), [types.expressionStatement (conditional), contiOrBreak]); cases.push (switchCase); ii += bodyArr.length + 1 ; } else { switchCase = types.switchCase (types.stringLiteral (caseTestArr[ii]), [v, types.expressionStatement (index), contiOrBreak]); cases.push (switchCase); ii += 1 ; } }); let i = cases.length ; while (i) { let j = Math .floor (Math .random () * i--); [cases[j], cases[i]] = [cases[i], cases[j]]; } let switchSta = types.switchStatement (_index, cases); let unaExp = types.unaryExpression ("!" , types.arrayExpression ()); unaExp = types.unaryExpression ("!" , unaExp); let whileSta = types.whileStatement (unaExp, types.blockStatement ([switchSta, types.breakStatement ()])); path.get ('body' ).replaceWith (types.blockStatement ([initor, whileSta])); } });
逗号表达式混淆 就是用逗号连接多个表达式,有些情况需要注意,比如声明语句之间的连接
1 2 3 4 var a = 100 ;var b = 200 ;var a = 100 ,b = 200 ;var a = 100 ,var b = 200 ;
从上述例子可以看出,如果两个声明语句要连接,需要取出VariableDeclaration中的declarations数组,里面是声明语句中定义的一个个变量,然后处理成一条声明语句,这里最方便的处理方式是把所有的标识符声明,都提取到参数中
逗号表达式混淆比较复杂,针对不同的语句有不同的处理方式,这里只针对上面的demo进行处理,如果是声明语句,就改成赋值语句,然后把变量提到函数参数中去,大概就是把 a=b,c=d 转成c=(a=b,d)这种形式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 traverse (ast, { FunctionExpression (path) { let blockStatement = path.node .body ; let blockStatementLength = blockStatement.body .length ; if (blockStatementLength < 2 ) return ; path.traverse ({ VariableDeclaration (p) { declarations = p.node .declarations ; let statements = []; declarations.map (function (v ) { path.node .params .push (v.id ); v.init && statements.push (types.expressionStatement (types.assignmentExpression ('=' , v.id , v.init ))); }); p.replaceInline (statements); } }); let firstSta = blockStatement.body [0 ], i = 1 ; let staArr = []; while (i < blockStatementLength) { let tempSta = blockStatement.body [i++]; types.isExpressionStatement (tempSta) ? secondSta = tempSta.expression : secondSta = tempSta; if (types.isWhileStatement (firstSta)) { firstSta = secondSta; continue ; } if (types.isReturnStatement (secondSta)) { staArr.push (secondSta); } else if (types.isAssignmentExpression (secondSta)) { if (types.isCallExpression (secondSta.right )) { let callee = secondSta.right .callee ; callee.object = types.toSequenceExpression ([firstSta, callee.object ]); firstSta = secondSta; } else { secondSta.right = types.toSequenceExpression ([firstSta, secondSta.right ]); firstSta = secondSta; } } else if (types.isWhileStatement (secondSta)) { staArr.push (firstSta); staArr.push (secondSta); firstSta = secondSta; } else { firstSta = types.toSequenceExpression ([firstSta, secondSta]); } } staArr.push (firstSta); staArr = staArr.map (function (v ) { if (!types.isStatement (v)) { return types.expressionStatement (v); } else { return v; } }) path.get ('body' ).replaceWith (types.blockStatement (staArr)); } });