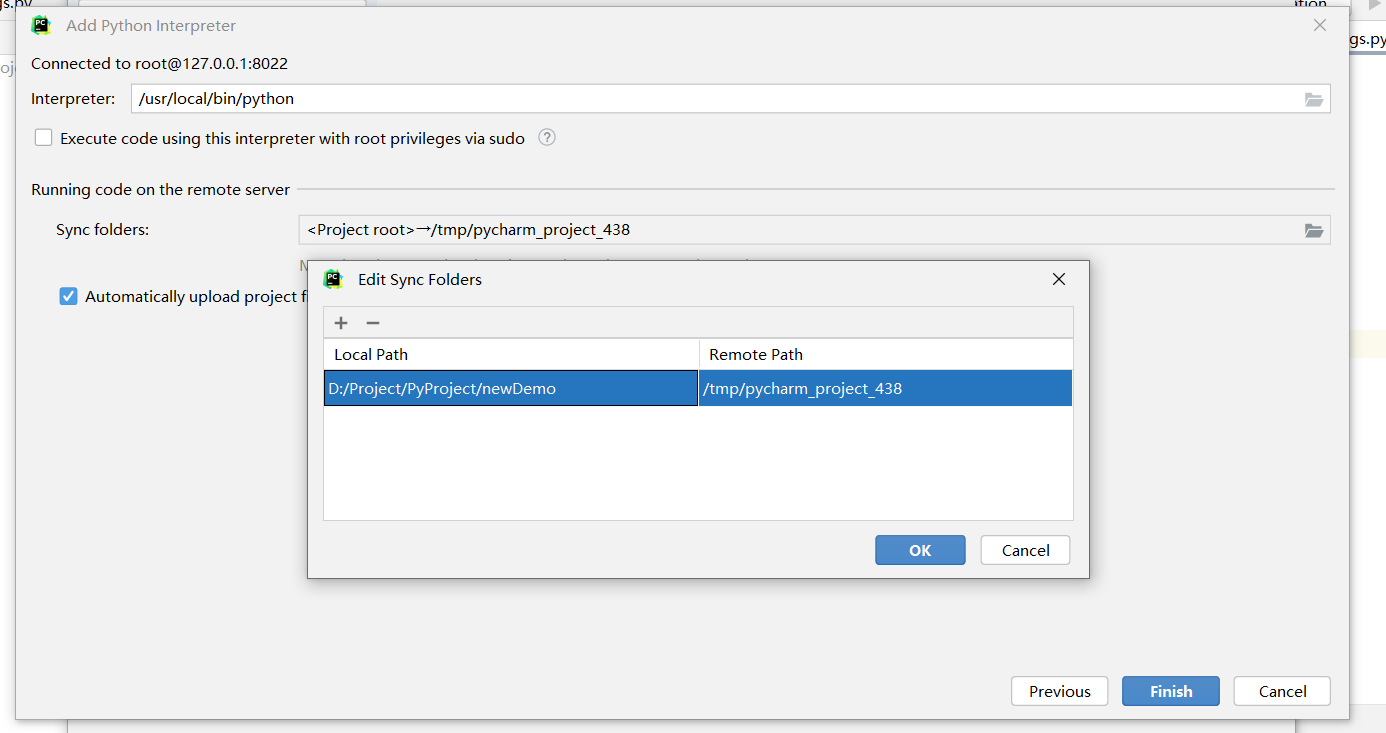
classJD: def__init__(self): self.headers={ 'referer': 'https://www.jd.com/', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36' }
defget_comment_num(self,sku): url='https://club.jd.com/comment/productCommentSummaries.action?referenceIds='+str(sku) html=requests.get(url,self.headers) if html.status_code==200: CommentCountStr=html.json()['CommentsCount'][0]['CommentCountStr'] return CommentCountStr returnNone
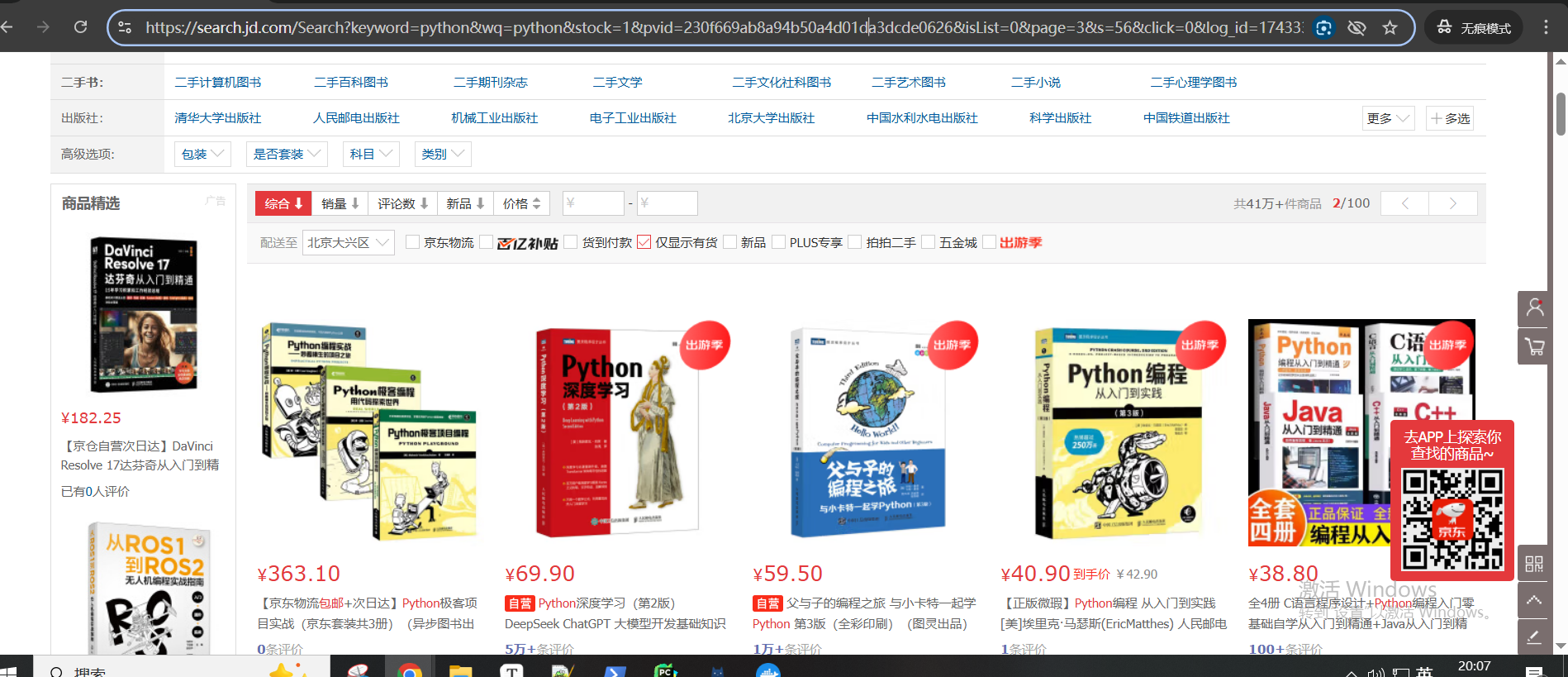
defstart(self): for i inrange(3): index_url=f'https://search.jd.com/Search?keyword=python&wq=python&pvid=13e1b05c465b41c6a91ab45c1386f90e&page={str(i)}' print(f'正在爬取第{i+1}页') html=requests.get(index_url,headers=self.headers) #print(html.text) if html.status_code==200: soup=BeautifulSoup(html.text,'lxml') lis=soup.select('ul.gl-warp.clearfix li') for li in lis: product_name=li.select_one('.gl-i-wrap .p-name a').text.strip().replace('\n','') product_img='https:'+li.select_one('.gl-i-wrap .p-img a img')['data-lazy-img'] product_price=li.select_one('.gl-i-wrap .p-price strong i').text product_shopname=li.select_one('.gl-i-wrap .p-shopnum a') if product_shopname: product_shopname=product_shopname.text
defstart(self): for i inrange(3): index_url=f'https://search.jd.com/Search?keyword=python&wq=python&pvid=13e1b05c465b41c6a91ab45c1386f90e&page={str(i)}' print(f'正在爬取第{i+1}页') headers=self.headers headers['referer']='https://www.jd.com/' html=requests.get(index_url,headers=headers) #print(html.text) if html.status_code==200: soup=BeautifulSoup(html.text,'lxml') lis=soup.select('ul.gl-warp.clearfix li') skus=[] #爬取上半页 for li in lis: product_name=li.select_one('.gl-i-wrap .p-name a').text.strip().replace('\n','') product_img='https:'+li.select_one('.gl-i-wrap .p-img a img')['data-lazy-img'] product_price=li.select_one('.gl-i-wrap .p-price strong i').text product_shopname=li.select_one('.gl-i-wrap .p-shopnum a')
if product_shopname: product_shopname=product_shopname.text
classJD: def__init__(self): self.headers={ 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36 Edge/18.17763' }
defget_comment_num(self,sku): url='https://club.jd.com/comment/productCommentSummaries.action?referenceIds='+str(sku) html=requests.get(url,self.headers) if html.status_code==200: CommentCountStr=html.json()['CommentsCount'][0]['CommentCountStr'] return CommentCountStr returnNone
defget_comment_data(self,url): #https://item.jd.com/34608882177.html if url.startswith('//'): url='https:'+url product_id=url.split('/')[-1].split('.')[0]
for i inrange(0,100): url='https://club.jd.com/comment/productPageComments.action' params={ 'productId': product_id, 'score': '0', 'sortType': '5', 'page': i, 'pageSize': '10', 'isShadowSku': '0', 'fold': '1' } try: html=requests.get(url,params=params,headers=self.headers) print(html.text) if html.json()['comments']: coms=html.json()['comments'] for c in coms: print("com:",c) except json.decoder.JSONDecodeError: pass
exit(0)
defget_another_product(self,skus,page,index_url): sku_str='' for num,s inenumerate(skus): if num==len(skus)-1: sku_str+=s break sku_str+=s+','
url=f'https://search.jd.com/s_new.php?keyword=python&wq=python&pvid=13e1b05c465b41c6a91ab45c1386f90e&page={page}&show_items={sku_str}' headers=self.headers headers['referer']=index_url html=requests.get(url,headers=headers) soup=BeautifulSoup(html.text,'lxml') lis=soup.select('li') for li in lis: product_name=li.select_one('.gl-i-wrap .p-name a').text.strip().replace('\n','') #内部URL product_inner_url=li.select_one('.gl-i-wrap .p-name a')['href'] product_img='https:'+li.select_one('.gl-i-wrap .p-img a img')['data-lazy-img'] product_price=li.select_one('.gl-i-wrap .p-price strong i').text product_shopname=li.select_one('.gl-i-wrap .p-shopnum a') if product_shopname: product_shopname=product_shopname.text
defstart(self): for i inrange(0,1): index_url=f'https://search.jd.com/Search?keyword=python&wq=python&pvid=13e1b05c465b41c6a91ab45c1386f90e&page={str(i)}' print(f'正在爬取第{i+1}页') headers=self.headers headers['referer']='https://www.jd.com/' html=requests.get(index_url,headers=headers) #print(html.text) if html.status_code==200: soup=BeautifulSoup(html.text,'lxml') lis=soup.select('ul.gl-warp.clearfix li') skus=[] #爬取上半页 for li in lis: product_name=li.select_one('.gl-i-wrap .p-name a').text.strip().replace('\n','') product_img='https:'+li.select_one('.gl-i-wrap .p-img a img')['data-lazy-img'] product_price=li.select_one('.gl-i-wrap .p-price strong i').text product_shopname=li.select_one('.gl-i-wrap .p-shopnum a')
if product_shopname: product_shopname=product_shopname.text
defstart(self): for i inrange(0,2): index_url=f'https://search.jd.com/Search?keyword=python&wq=python&pvid=13e1b05c465b41c6a91ab45c1386f90e&page={str(i)}' print(f'正在爬取第{i+1}页') headers=self.headers headers['referer']='https://www.jd.com/' html=requests.get(index_url,headers=headers) #print(html.text) if html.status_code==200: soup=BeautifulSoup(html.text,'lxml') lis=soup.select('ul.gl-warp.clearfix li') skus=[] #爬取上半页 for li in lis: product_name=li.select_one('.gl-i-wrap .p-name a').text.strip().replace('\n','') product_img='https:'+li.select_one('.gl-i-wrap .p-img a img')['data-lazy-img'] product_price=li.select_one('.gl-i-wrap .p-price strong i').text product_shopname=li.select_one('.gl-i-wrap .p-shopnum a')
if product_shopname: product_shopname=product_shopname.text